Filtrando y respondiendo tweets "sin manos"
Para reproducir este post necesitarás:
-
docker y docker-compose instalado en una máquina (puede ser una RaspberryPi)
-
Claves OAuth de aplicación de Twitter que tienes que obtener rellenando un formulario en https://developer.twitter.com/en/apps
Objetivo
Vamos a lanzar un proceso desatendido que va a estar atento a todos los tweets que se vayan produciendo en la red social y que contenga una o varias palabras claves de nuestro interés, por ejemplo "PuraVida"
Cuando se detecte un tweet con esta(s) palabras claves realizaremos un segundo filtrado para comprobar si la palabra está en un "contexto" que nos interesa. Por ejemplo vamos a buscar que el texto del tweet contenga "Costa Rica" y cuando se encuentre vamos a contestar con un tweet predefinido, por ejemplo "PuraVida mae" (una expresión tica que me enamoró cuando la escuché por primera vez)
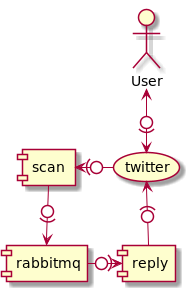
Arquitectura
Para conseguir que la parte que lee eventos de Twitter no se demore con procesos de búsqueda de texto en el mensaje, envío de un tweet, etc vamos a crear dos procesos independientes donde uno va a estar escuchando los eventos de Twitter y enviándolos a una cola de Rabbit mientras que otro proceso va a leer de esta cola y enviará el tweet si procede
De esta forma aseguramos una lectura fluida de los eventos producidos en la red y los guardamos en una cola interna listos para ir siendo procesados
(Esta misma arquitectura podemos ampliarla para escanear por más de un concepto y redirigir a diferentes colas según cada uno)
Oauth
En primer lugar tendremos que rellenar el formulario indicado al principio y obtener unas claves (4). Este proceso puede demorar algunos días e incluso pueden rechazarte la petición si no lo rellenaste con la suficiente información.
Una vez que los tengas crearemos un fichero tal como este en el directorio que vayamos a usar para este proyecto.
twitterj4.properties
oauth.consumerKey=xxxxxxxxx
oauth.consumerSecret=xxxxxxxxxxxxxxxxxxxxxx
oauth.accessToken=yyyyyyy-zzzzzzzzzzzzz
oauth.accessTokenSecret=zzzzzzzzzzzzzzzzzzzzzConfiguración
La configuración va a consistir en un fichero .env (ojo que
el nomre del fichero empieza en punto):
.env
SEARCH=puravida
FILTER='Costa Rica'
ANSWER='PuraVida mae'
IGNORE=jagednEs decir: vamos a buscar por la palabra puravida, vamos a filtrar aquellos
que lleven la frase Costa Rica y a los que cumplan las condiciones
les contestaremos con un RT PuraVida mae.
Para evitar "una recursividad" ignoraremos aquella cuenta cuyo autor sea nuestra propia cuenta
Docker
Los tres componentes de la solución (rabbitmq, scan y reply) van a trabajar de forma conjunta mediante un docker-compose:
version: '3'
services:
rabbitmq:
image: 'rabbitmq:3-management'
ports:
- '5672:5672'
- '15672:15672'
healthcheck:
test: [ "CMD", "nc", "-z", "localhost", "5672" ]
interval: 10s
timeout: 10s
retries: 5
scan:
image: groovy
volumes:
- .:/home/groovy
environment:
- SEARCH
command: "groovy scan.groovy rabbitmq $SEARCH"
depends_on:
- rabbitmq
reply:
image: groovy
volumes:
- .:/home/groovy
environment:
- IGNORE
- FILTER
- ANSWER
command: "groovy react.groovy rabbitmq $IGNORE $FILTER $ANSWER"
depends_on:
- rabbitmqComo rabbit tarda unos segundos en arrancar la primera vez que se ejecuta, lo lanzaremos en primer lugar y le dejaremos unos 10 segundos hasta que este preparado para recibir mensajes. Existen técnicas más sofisticadas para ello, pero en este post no vamos a complicarnos:
docker-compose up -d rabbitmq
Si queremos ver los logs y comprobar que el servicio arranca sin problemas:
docker-compose logs -f
Cuando veamos que el servicio se encuentra levantado cortamos el proceso con Ctrl+C
Scan
Una vez que Rabbit está listo podríamos lanzar los otros dos componentes simplemente ejecutando
docker-compose up -d
y ambos componentes empezarían a trabajar de forma coordinada.
Sin embargo para explicar cada uno de ellos lo vamos a ejecutar por ahora por separado:
docker-compose up -d scan
docker-compose logs -f scan
En consola deberemos ver cómo van apareciendo una serie de puntos según se vayan produciendo en Twitter. Obviamente si tu palabra a buscar no es muy popular a lo mejor tardas en verlo así que puedes empezar con algún término de rabiosa actualidad del momento (por ejemplo Ayuso)
@Grab('org.twitter4j:twitter4j-stream:4.0.7')
@Grab(group='com.rabbitmq', module='amqp-client', version='3.1.2')
import com.rabbitmq.client.*
import groovy.json.*
import twitter4j.*
exchangeName="groovy-script"
queueName="grabbit"
routingKey='#'
factory = new ConnectionFactory()
factory.username='guest'
factory.password='guest'
factory.virtualHost='/'
factory.host= args[0]
factory.port=5672
conn = factory.newConnection() (1)
channel = conn.createChannel()
channel.exchangeDeclare(exchangeName, "direct", true)
channel.queueDeclare(queueName, true, false, false, null)
channel.queueBind(queueName, exchangeName, routingKey) (2)
tweetFilterQuery = new FilterQuery()
tweetFilterQuery.track(args[1].split(','))
tweetFilterQuery.language('es') (3)
stream = new TwitterStreamFactory().instance
.addListener([
onStatus:{ status->
String json = JsonOutput.toJson([
statusId: status.id,
name: status.user.screenName,
text: status.text
]) (4)
channel.basicPublish(exchangeName, routingKey, null, json.bytes)
println "."
},
onException:{ },
onDeletionNotice:{},
onTrackLimitationNotice:{},
onScrubGeo:{},
onStallWarning:{},
] as StatusListener)
.filter(tweetFilterQuery)| 1 | Creamos una factoria de rabbit |
| 2 | Creamos y nos adjuntamos a una cola de rabbit |
| 3 | Creamos los criterios de búsqueda |
| 4 | Cada vez que recibimos un mensaje lo enviamos a la cola |
Como puedes ver casi todo el código es de infraestructura siendo lo más relevante cómo configuramos el FilterQuery y cómo convertimos
un status de twitter a un mensaje en la cola de rabbitmq
Básicamente podemos indicar una lista de palabras (en nuestro caso si el argumento SEARCH lo separamos con comas), por idioma, geoposición, etc
En la cola simplemente guardaremos el id, el usuario y el texto del tweet
React
Una vez que tenemos el proceso escaneando Twitter y enviando mensajes a nuestro rabbit es hora de consumirlos
Como rabbit va guardando los mensajes hasta que los consumamos podemos ejecutar el proceso de react después del scan:
docker-compose up -d react
docker-compose logs -f react
React, como scan, se conectará a la cola de rabbit e irá leyendo
json con el id, autor y texto del tweet. Simplemente buscará sin en dicho
texto aparece la cadena indica en FILTER y si es el caso comprobará
a su vez si la cuenta que originó el tweet es diferente a IGNORE.
Si es así enviará un status como RT al original con el texto indicado
@Grab('org.twitter4j:twitter4j-stream:4.0.7')
@Grab(group='com.rabbitmq', module='amqp-client', version='3.1.2')
import com.rabbitmq.client.*
import groovy.json.*
import twitter4j.*
exchangeName="groovy-script"
queueName="grabbit"
routingKey='#'
factory = new ConnectionFactory()
factory.username='guest'
factory.password='guest'
factory.virtualHost='/'
factory.host= args[0]
factory.port=5672
conn = factory.newConnection()
channel = conn.createChannel()
channel.exchangeDeclare(exchangeName, "direct", true)
channel.queueDeclare(queueName, true, false, false, null)
channel.queueBind(queueName, exchangeName, routingKey)
twitter = TwitterFactory.singleton
jsonSlurper = new JsonSlurper()
autoAck = true;
ignore = args[1]
msg = args[2]
answer = args.drop(3).join(' ')
println msg
println answer
channel.basicConsume(queueName, autoAck, new DefaultConsumer(channel) {
public void handleDelivery(String consumerTag,Envelope envelope,AMQP.BasicProperties properties,byte[] body) throws IOException{
String line = new String(body)
json = jsonSlurper.parseText(line)
if( json.text.toLowerCase().indexOf(msg) != -1 ){
println "$json.name:\n$json.text\n-------"
if( answer && json.name != ignore ){
stat= new StatusUpdate("@$json.name $answer")
stat.inReplyToStatusId = json.statusId as long
twitter.updateStatus(stat)
}
}
}
});El código es muy simpilar al de scan a la hora de conectarse a rabbitmq y lo que hace es simplemente consumir eventos de la cola
Para cada mensaje que llegue se comprueba si contiene la cadena a filtar
y se envía un tweet con inReplyToStatusId
Bots
Usando estos dos scripts puedes hacer bots que realicen acciones ante ciertos tweets:
-
hacer un retweet ante una palabra
-
guardar cuentas de usuario que mencionen una frase
-
etc
Por ejemplo podrías "tomar el pulso" a Twitter filtrando por una serie de palabras y actualizando en tiempo real una aplicación web donde se mostrara el número de veces que se están usando esas palabras