mn create-app --lang groovy --profile cli com.puravida.biblios.etlKubernetes, Jobs (3)
- noviembre, 30 2019
- Jorge Aguilera
- 05:00
This is the third part of a series of posts about how I’ll develop an application in Kubernetes (k8s)
-
first post: Idea (https://jorge.aguilera.soy/blog/prestamos-bibliotecas/k8s-1.html)
-
second post: Infraestructure (https://jorge.aguilera.soy/blog/prestamos-bibliotecas/k8s-2.html)
-
third post: Job (https://jorge.aguilera.soy/blog/prestamos-bibliotecas/k8s-3.html)
The main ot these posts is to document the process of deploying a solution in k8s at the same time I’m writting the application so probably all posts will have a lot of errors and mistakes that I need to correct in the next post.
| Be aware that I’m a very nobel with Kubernetes and these are my first steps with it. I hope to catch up the attention of people with more knowledge than me and maybe they can review these posts and suggest to us some improvements. |
| I’ve created a git repository at https://gitlab.com/puravida-software/k8s-bibliomadrid with the code of the application |
Gradle multiproject
I’ve splitted the application into a multimodule Gradle projects with:
-
com-puravida-biblios-model as a Micronaut jar library with the model and the repository. Also this library will have the liquidbase files to update the database schema
-
com-puravida-biblios-etl as a Micronaut cli application who takes a year and a month as arguments to download the csv file and import it into the database.
These are typical project created with the cli as:
As at some point I’ll need a database (PostgreSQL) I use Okteto’s hability to develop an application into a kubernetes cluster with a PostgreSQL deployed (see step2) in a similar way as if I use a local instance of PostgreSQL or TestContainer,etc.
| For this use case, Okteto doesn’t add a lot of value because I have only a database dependency that I can solve with local solutions. If the application requires more artifacts as specific services, databases or tools that are difficult to install and maintain in every developer desktop, Okteto can be a good solution to develop directly in a kubernetes cluster. |
So basically I’ve created an okteto.ini file in the root of the gradle proyect
okteto.ini
name: gradle
image: gradle:latest
command:
- bash
volumes:
- /home/gradle/.gradle
forward:
- 8080:8080
- 8088:8088
environment:
- POSTGRES_PASSWORD=okteto
- POSTGRES_USER=okteto
- POSTGRES_DB=okteto
- POSTGRESQL_SERVICE_HOST=10.0.7.172And when I want to develop directly in the cluster I only need to execute:
$ okteto up
groovy:groovy$ ./gradlew buildWith okteto up I created a new Pod called gradle with the gradle docker image
where I can run commands as build, run, etc.
Also I can edit files in my local disk and okteto will synchronize them with the remote pod. In the same way I can run the application in the pod and connect to it with my IntelliJ in order to debug it as if it was running in my laptop
As you can see I’ve injected some environment values related to my Postgre database so the application can works against it (insert records at develop time, etc)
Model
By the moment the model is very simple with only two Domain Object and two repositories:
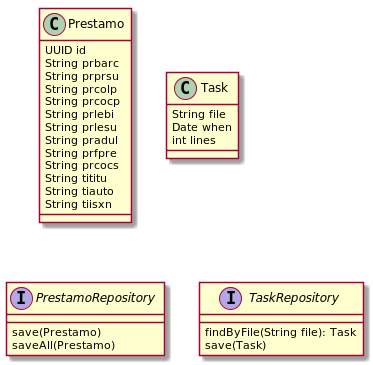
Job
Once I had the etl ready, able to download a file and parse and insert into the database
I wanted to have a kubernetes way to run it using differents years and months.
One posibility is to have a pod and via command line or with a web endpoint invoque the import process but in this case I’ve used a Job.
Kubernetes has the possibility to run a container via a Job in a lot of different scenaries (one-shot, with a chron, rety if fails, etc). For my purpose I want to run a single Job, and launch it mannualy (once I verified a new file is ready in the portal of OpenData).
This job needs to connect to the database so I’ll need to use the ConfigMap where I saved the connection details (host, user, password and database). Also I need to indicate the year and month to process (via arguments command line)
After some reseachs (trial and error) I learnt some lessons:
-
When you run a Job (with
kubectl apply -f job-file.yamlfor example), kubernetes creates a new pod and meanwhile you don’t remove it withkubectl delete name-of-the-job-idit remains into your cluster (as finished). This can be usefull to inspect the logs for example -
You can run a Job multiple times and kubernetes will create new pods every time but you need to inspect what’s the last executed.
-
Once executed a Job you CAN’T modify the spec and try again to run it. You’ll have a field inmmutable error. To solve it simple delete the old job and retry
As I want to run a job using different arguments (year and month) I can’t use a single yaml file
without deleting jobs previously executed, so I ended with a template, and using sed command
I replace some variables to produce final yaml files:
apiVersion: batch/v1
kind: Job
metadata:
name: com-puravida-biblios-etl-$YEAR-$MONTH
labels:
jobgroup: etl
spec:
backoffLimit: 0
template:
spec:
containers:
- name: com-puravida-biblios-etl
image: jagedn/k8s-bibliomadrid-etl:$VERSION
args: [ "-y", "$YEAR", "-m", "$MONTH"]
envFrom:
- configMapRef:
name: postgres-config
restartPolicy: Never
terminationGracePeriodSeconds: 0as you can see we have 3 variables (YEAR, MONTH and VERSION) to replace
etl-tpl.yaml
$ sed -e 's/$YEAR/2019/g' -e 's/$MONTH/04/g' -e 's/$VERSION/0.1/g' k8s/etl-tpl.yaml > k8s/jobs/etl-2019-04.yaml
$ kubectl apply -f k8s/jobs/etl-2019-04.yaml
$ kubectl logs -f com-puravida-biblios-etl-2019-06-fdx6fIn this way not only I’ll have one file per year-month that I can run in every namespace I had (dev and prod) but also I’ll have in the repo all files versioned
Next step
Once we have some datas into our database we can develop a new service able to serve them via REST (or maybe GrapQL?) to Internet
Acknowledgment
Thanks to Pablo Chico de Guzman, @pchico83, to confirm a Job is a good alternative to do a ETL
Thanks to JJ Merelo, @jjmerelo, for suggesting me to use Celery (https://twitter.com/jjmerelo/status/1199935927931592705) Another tool to learn!!!
Thanks to Fran, @franco87ES, for confirm I can use ConfigMap in a Job (https://twitter.com/franco87ES/status/1200059717965504513) I was lost because after modified a yaml I wanted to re-apply it, without removed the old job and Kubernetes was rejecting the action with a 'field inmutable' error and I thought was due to the ConfigMap section. Thanks to Fran’s advice I digged more into the problem and at the end I realized my error.